设计工作流
Signatures
2.0新增功能。
在调用任务章节我们讲了如何通过delay 方法调用任务,通常这就是你所需要的全部,但有时您可能希望将任务调用的签名传递给另一个进程或作为另一个函数的参数。
signature()以某种方式包装单个任务调用的参数、关键字参数和执行选项,以便可以将其传递给函数,甚至可以通过网络进行序列化和发送。
可以使用任务名称来创建一个签名,比如给
add创建一个签名:>>> from celery import signature >>> signature('tasks.add', args=(2, 2), countdown=10) tasks.add(2, 2)This task has a signature of arity 2 (two arguments):
(2, 2), and sets the countdown execution option to 10.或者使用任务的
signature方法创建:>>> add.signature((2, 2), countdown=10) tasks.add(2, 2)还有个快捷方式:
>>> add.s(2, 2) tasks.add(2, 2)也支持关键字参数:
>>> add.s(2, 2, debug=True) tasks.add(2, 2, debug=True)您可以从任何签名实例检查不同的字段:
>>> s = add.signature((2, 2), {'debug': True}, countdown=10) >>> s.args (2, 2) >>> s.kwargs {'debug': True} >>> s.options {'countdown': 10}签名也支持
delay和apply_async的“调用API”,包括直接调用(call)。调用签名,将直接在当前进程中执行任务:
>>> add(2, 2) 4 >>> add.s(2, 2)() 4delay是我们代替apply_async的快捷方式:>>> result = add.delay(2, 2) >>> result.get() 4apply_async采用与 app.Task.apply_async() 相同的调用参数。>>> add.apply_async(args, kwargs, **options) >>> add.signature(args, kwargs, **options).apply_async() >>> add.apply_async((2, 2), countdown=1) >>> add.signature((2, 2), countdown=1).apply_async()你不能通过 s() 定义执行选项,但是可以通过 set 的链式调用解决:
>>> add.s(2, 2).set(countdown=1) proj.tasks.add(2, 2)
Partials
拿着签名你可以在worker中执行任务
>>> add.s(2, 2).delay()
>>> add.s(2, 2).apply_async(countdown=1)
或者直接在当前进程中执行:
>>> add.s(2, 2)()
4
可以给 delay/apply_async 指定额外的参数、关键词参数或执行选项:
Specifying additional args, kwargs, or options to apply_async/delay creates partials:
添加的任何参数都将附加到签名中的参数之前:
>>> partial = add.s(2) # incomplete signature >>> partial.delay(4) # 4 + 2 >>> partial.apply_async((4,)) # same添加的任何关键字参数都将与签名中的kwarg合并,新的关键字参数优先:
>>> s = add.s(2, 2) >>> s.delay(debug=True) # -> add(2, 2, debug=True) >>> s.apply_async(kwargs={'debug': True}) # same添加的任何选项都将与签名中的选项合并,新选项优先:
>>> s = add.signature((2, 2), countdown=10) >>> s.apply_async(countdown=1) # countdown is now 1
您还可以克隆签名以创建衍生签名:
>>> s = add.s(2)
proj.tasks.add(2)
>>> s.clone(args=(4,), kwargs={'debug': True})
proj.tasks.add(4, 2, debug=True)
Immutability
Partials意味着与回调一起使用,任何连接的任务或者和弦回调(chord callbacks)都将与父任务的结果一起应用。有时候你想指定一个不带附加参数的回调函数,在这种情况下,你可以将签名设置为immutable(不可变的):
>>> add.apply_async((2, 2), link=reset_buffers.signature(immutable=True))
还有个快捷方式.si():
>>> add.apply_async((2, 2), link=reset_buffers.si())
当签名是不可变时,只能设置执行选项,因此不能携带partial args/kwargs调用签名。
Note:
在本教程中,我有时会使用前缀操作符
~来表示签名。不过最好不要在生产代码中使用,但在Python shell中进行试验时,它是一个方便的快捷方式:>>> ~sig >>> # is the same as >>> sig.delay().get()
Callbacks
通过给apply_async传递link参数,你可以给所有任务添加回调:
add.apply_async((2, 2), link=other_task.s())
只有当任务成功退出时才应用回调,并且将以父任务的返回值作为参数来应用它。
正如我前面提到的,您添加到签名中的任何参数都将被添加到签名本身指定的参数之前!
比如你有个签名:
>>> sig = add.s(10)
那么sig.delay(result)会变成:
>>> add.apply_async(args=(result, 10))
...
现在,让我们使用partial参数来调用一个有着回调的add任务:
>>> add.apply_async((2, 2), link=add.s(8))
正如预期的那样,这将首先启动一个任务计算2+2,然后另一个计算4+8
The Primitives
3.0新增功能
概览
group
The group primitive is a signature that takes a list of tasks that should be applied in parallel.
group primitive是一个包含一个任务列表的签名,列表中的任务应该并行应用。
chain
The chain primitive lets us link together signatures so that one is called after the other, essentially forming a chain of callbacks.
chain primitive允许我们将签名连接到一起,以便一个接一个地被调用,实质上形成了一个回调链。
chord
A chord is just like a group but with a callback. A chord consists of a header group and a body, where the body is a task that should execute after all of the tasks in the header are complete.
chord和group很像,但多了个回调。一个chord包含一个header group和一个body,body是一个应该在header中的任务完成之后才执行的任务。
map
The map primitive works like the built-in
mapfunction, but creates a temporary task where a list of arguments is applied to the task. For example,task.map([1,2])– results in a single task being called, applying the arguments in order to the task function so that the result is:res = [task(1), task(2)]starmap
Works exactly like map except the arguments are applied as
*args. For exampleadd.starmap([(2, 2), (4, 4)])results in a single task calling:res = [add(2, 2), add(4, 4)]chunks
Chunking splits a long list of arguments into parts, for example the operation:
>>> items = zip(range(1000), range(1000)) # 1000 items >>> add.chunks(items, 10)will split the list of items into chunks of 10, resulting in 100 tasks (each processing 10 items in sequence).
这些primitives本身也是签名对象,因此它们可以以多种方式组合以组成复杂的工作流。
这儿有一些示例:
Simple chain
这是一个简单的链,第一个任务将其返回值传递给链上的下一个任务,等等。
>>> from celery import chain >>> # 2 + 2 + 4 + 8 >>> res = chain(add.s(2, 2), add.s(4), add.s(8))() >>> res.get() 16还可以使用管道符连接:
>>> (add.s(2, 2) | add.s(4) | add.s(8))().get() 16Immutable signatures
签名可以是partial(部分的),因此可以在已存在的参数上附加参数。不过有时候你可能不想这样,比如您不想要链中上一个任务的结果。
在这种情况下,您可以将签名标记为Immutable(不可变),以便无法更改参数:
>>> add.signature((2, 2), immutable=True)它还有一个
.si()的快捷方式,并且这是创建签名的首选方式:>>> add.si(2, 2)现在,您可以改为创建一个独立任务链:
>>> res = (add.si(2, 2) | add.si(4, 4) | add.si(8, 8))() >>> res.get() 16 >>> res.parent.get() 8 >>> res.parent.parent.get() 4Simple Group
你可以很容易创建一组并行的任务:
>>> from celery import group >>> res = group(add.s(i, i) for i in range(10))() >>> res.get(timeout=1) [0, 2, 4, 6, 8, 10, 12, 14, 16, 18]Simple chord
The chord primitive enables us to add a callback to be called when all of the tasks in a group have finished executing. This is often required for algorithms that aren't
embarrassingly parallel:chord primitive 使我们能够添加一个回调函数,当组中的所有任务都执行完毕时调用该函数。这可以避免在某些算法中因并发导致的尴尬场景出现。
>>> from celery import chord >>> res = chord((add.s(i, i) for i in range(10)), xsum.s())() >>> res.get() 90上面的示例创建了十个并行任务,并且在完成之后将返回值组合成一个列表发送给
xsum任务。chord的主体也可以是不可变的(Immutable),这样组的返回值就不会传递给回调函数:
>>> chord((import_contact.s(c) for c in contacts), ... notify_complete.si(import_id)).apply_async()请注意上面
.si的用法,这创建了一个不可变的(Immutable)签名,意味着任何传递的新参数(包括返回前一个任务的值)都将被忽略。Blow your mind by combining
Chains也可以是partial的:
>>> c1 = (add.s(4) | mul.s(8)) # (16 + 4) * 8 >>> res = c1(16) >>> res.get() 160这意味着你可以组合chain
# ((4 + 16) * 2 + 4) * 8 >>> c2 = (add.s(4, 16) | mul.s(2) | (add.s(4) | mul.s(8))) >>> res = c2() >>> res.get() 352将group和另一个任务链接会自动升级为一个chord:
>>> c3 = (group(add.s(i, i) for i in range(10)) | xsum.s()) >>> res = c3() >>> res.get() 90Groups和chords同样接受partial参数,因此,在链中,前一个任务的返回值将转发给组中的所有任务:
>>> new_user_workflow = (create_user.s() | group( ... import_contacts.s(), ... send_welcome_email.s())) ... new_user_workflow.delay(username='artv', ... first='Art', ... last='Vandelay', ... email='art@vandelay.com')如果不想将参数转发给group,可以创建immutable的group:
>>> res = (add.s(4, 4) | group(add.si(i, i) for i in range(10)))() >>> res.get() <GroupResult: de44df8c-821d-4c84-9a6a-44769c738f98 [ bc01831b-9486-4e51-b046-480d7c9b78de, 2650a1b8-32bf-4771-a645-b0a35dcc791b, dcbee2a5-e92d-4b03-b6eb-7aec60fd30cf, 59f92e0a-23ea-41ce-9fad-8645a0e7759c, 26e1e707-eccf-4bf4-bbd8-1e1729c3cce3, 2d10a5f4-37f0-41b2-96ac-a973b1df024d, e13d3bdb-7ae3-4101-81a4-6f17ee21df2d, 104b2be0-7b75-44eb-ac8e-f9220bdfa140, c5c551a5-0386-4973-aa37-b65cbeb2624b, 83f72d71-4b71-428e-b604-6f16599a9f37]> >>> res.parent.get() 8
Chains
3.0新增
任务可以链接在一起:当任务成功返回时,将调用链接的任务:
>>> res = add.apply_async((2, 2), link=mul.s(16))
>>> res.get()
4
链接的任务会将其父任务的结果作为第一个参数。In the above case where the result was 4, this will result in mul(4, 16)。
results会持续追踪任何被原始任务调用的子任务。这可以从result实例中访问:
>>> res.children
[<AsyncResult: 8c350acf-519d-4553-8a53-4ad3a5c5aeb4>]
>>> res.children[0].get()
64
The result instance also has a collect() method that treats the result as a graph, enabling you to iterate over the results:
>>> list(res.collect())
[(<AsyncResult: 7b720856-dc5f-4415-9134-5c89def5664e>, 4),
(<AsyncResult: 8c350acf-519d-4553-8a53-4ad3a5c5aeb4>, 64)]
默认情况下,在graph还没有完全填充(有任务还没完成)时collec()会导致一个IncompleteStream的异常,不过,你可以获取graph的中间态:
>>> for result, value in res.collect(intermediate=True):
....
您可以将任意多个任务链接在一起,也可以链接签名:
>>> s = add.s(2, 2)
>>> s.link(mul.s(4))
>>> s.link(log_result.s())
还可以使用on_error方法添加error callbacks:
>>> add.s(2, 2).on_error(log_error.s()).delay()
This will result in the following .apply_async call when the signature is applied:
>>> add.apply_async((2, 2), link_error=log_error.s())
worker 不会将errback作为任务调用,而是直接调用errback函数以便将原始请求、异常以及traceback对象传递过去。
这是一个errback的示例:
from __future__ import print_function
import os
from proj.celery import app
@app.task
def log_error(request, exc, traceback):
with open(os.path.join('/var/errors', request.id), 'a') as fh:
print('--\n\n{0} {1} {2}'.format(
request.id, exc, traceback), file=fh)
为了更容易地将任务链接在一起,有一个特殊的签名,叫做chain,它可以让你将任务链接在一起:
>>> from celery import chain
>>> from proj.tasks import add, mul
>>> # (4 + 4) * 8 * 10
>>> res = chain(add.s(4, 4), mul.s(8), mul.s(10))
proj.tasks.add(4, 4) | proj.tasks.mul(8) | proj.tasks.mul(10)
Calling the chain will call the tasks in the current process and return the result of the last task in the chain
调用chain将在当前进程中调用任务,并返回chain中最后一个任务的结果
>>> res = chain(add.s(4, 4), mul.s(8), mul.s(10))()
>>> res.get()
640
它还设置了parent属性,这样你就可以沿着链向上以获得中间结果:
>>> res.parent.get()
64
>>> res.parent.parent.get()
8
>>> res.parent.parent
<AsyncResult: eeaad925-6778-4ad1-88c8-b2a63d017933>
Chains也可以使用管道符
>>> (add.s(2, 2) | mul.s(8) | mul.s(10)).apply_async()
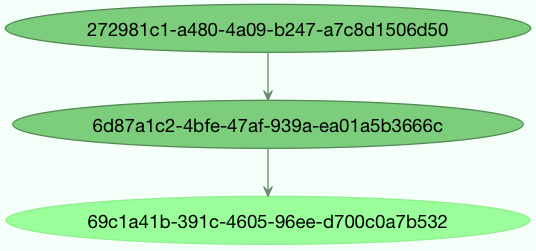
Graphs
此外,您还可以将结果图形作为DependencyGraph来使用:
>>> res = chain(add.s(4, 4), mul.s(8), mul.s(10))()
>>> res.parent.parent.graph
285fa253-fcf8-42ef-8b95-0078897e83e6(1)
463afec2-5ed4-4036-b22d-ba067ec64f52(0)
872c3995-6fa0-46ca-98c2-5a19155afcf0(2)
285fa253-fcf8-42ef-8b95-0078897e83e6(1)
463afec2-5ed4-4036-b22d-ba067ec64f52(0)
您甚至可以将这些graps转换为dot格式:
>>> with open('graph.dot', 'w') as fh:
... res.parent.parent.graph.to_dot(fh)
创建图像:
$ dot -Tpng graph.dot -o graph.png
Groups
3.0新增
group可用于并行执行多个任务。
The group function takes a list of signatures:
>>> from celery import group
>>> from proj.tasks import add
>>> group(add.s(2, 2), add.s(4, 4))
(proj.tasks.add(2, 2), proj.tasks.add(4, 4))
如果调用group,任务将会在当前进程中一个接一个应用,并且返回一个GroupResult实例。可以用来追踪结果或任务执行到哪儿了等:
>>> g = group(add.s(2, 2), add.s(4, 4))
>>> res = g()
>>> res.get()
[4, 8]
Group支持迭代器:
>>> group(add.s(i, i) for i in range(100))()
一个group是一个签名对象,因此可以和其他签名进行组合。
Group Callbacks and Error Handling:Group回调和错误处理
Group也可以有callback和errback,但是其行为可能有些不同,这主要是因为groups并非真正的任务,它实际上只是将链接的任务向下传递传递到其封装的签名。这意味着不会收集组的返回值以传递给链接的callback。例如,以下使用简单 add(a, b) 任务的代码片段是错误的,因为链接的 add.s() 签名不会像预期的那样接收最终的组结果。
>>> g = group(add.s(2, 2), add.s(4, 4))
>>> g.link(add.s())
>>> res = g()
[4, 8]
请注意,返回前两个任务的最终结果,但回调将在后台运行并引发异常,因为它没有收到它期望的两个参数。
Group errbacks 也被传递给封装的签名,如果组中的多个任务失败,则可能会多次调用仅链接一次的 errback。例如,使用引发异常的 fail() 任务的以下代码片段可以预期为在group中运行的每个失败任务调用一次 log_error() 签名。
>>> g = group(fail.s(), fail.s())
>>> g.link_error(log_error.s())
>>> res = g()
With this in mind, it’s generally advisable to create idempotent or counting tasks which are tolerant to being called repeatedly for use as errbacks.
These use cases are better addressed by the chord class which is supported on certain backend implementations.
Group Results
group任务也返回一个特殊的结果,此结果的工作方式与正常任务结果相同,只是它将组作为一个整体来处理
>>> from celery import group
>>> from tasks import add
>>> job = group([
... add.s(2, 2),
... add.s(4, 4),
... add.s(8, 8),
... add.s(16, 16),
... add.s(32, 32),
... ])
>>> result = job.apply_async()
>>> result.ready() # have all subtasks completed?
True
>>> result.successful() # were all subtasks successful?
True
>>> result.get()
[4, 8, 16, 32, 64]
GroupResult 采用 AsyncResult 实例的列表并对其进行操作,就好像它是一个单独的任务一样。
It supports the following operations:
successful()
如果所有子任务成功结束,则返回True
failed()
任一子任务失败则返回True
waiting()
任一子任务未就绪则返回True
ready()
所有子任务就绪返回True
completed_count()
返回完成的子任务数值
revoke()
撤销所有子任务
join()
收集所有子任务的结果,并以调用它们的相同顺序返回它们(作为列表)。
Chords
2.3新增
Note:
使用chord的任务必须不能忽略results。如果有任务(header或body)禁用了backend你都应该阅读Important Notes:重要提示。此外,Chords不支持RPC后端。
一个chord是一个任务,只在group中的所有任务完成之后才会执行。
让我们计算以下算式:1+1+2+2+3+3+...+100+100
首先你需要两个任务,add()和tsum()(sum()是标准函数)
@app.task
def add(x, y):
return x + y
@app.task
def tsum(numbers):
return sum(numbers)
然后可以使用chord并行计算每个加法步骤,然后得到结果数字的总和:
>>> from celery import chord
>>> from tasks import add, tsum
>>> chord(add.s(i, i)
... for i in range(100))(tsum.s()).get()
9900
这是一个人为的演示示例,消息传递和同步的开销比Python对应方式慢很多:
>>> callback = tsum.s()
>>> header = [add.s(i, i) for i in range(100)]
>>> result = chord(header)(callback)
>>> result.get()
9900
请记住,只有在header中的所有任务都返回后才能执行回调。 header中的每个步骤都作为一个任务并行执行,可能在不同的节点上执行。 然后将回调与header中每个任务的返回值一起应用。 chord()返回的任务id就是回调的id,所以你可以等待它完成并得到最终的返回值(但切记永远不要让一个任务等待其他任务)
Error handling:错误处理
那么一个任务触发异常的时候发生了什么呢?
Chord回调结果将转换为失败状态,并且错误将设置为ChordError异常:
>>> c = chord([add.s(4, 4), raising_task.s(), add.s(8, 8)])
>>> result = c()
>>> result.get()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "*/celery/result.py", line 120, in get
interval=interval)
File "*/celery/backends/amqp.py", line 150, in wait_for
raise meta['result']
celery.exceptions.ChordError: Dependency 97de6f3f-ea67-4517-a21c-d867c61fcb47
raised ValueError('something something',)
根据后端不同traceback也会有所不同,您可以看到错误描述包括失败任务的 id 和原始异常的字符串表示形式。 您还可以在result.traceback中找到原始的traceback。
请注意,其余任务仍将执行,因此即使中间任务失败,第三个任务(add.s(8,8))仍将执行。此外,ChordError仅显示第一个失败的任务(按时间):它不考虑header group的顺序。
因此,要在chrod失败时执行操作,您可以将 errback 附加到chrod回调:
@app.task
def on_chord_error(request, exc, traceback):
print('Task {0!r} raised error: {1!r}'.format(request.id, exc))
>>> c = (group(add.s(i, i) for i in range(10)) |
... xsum.s().on_error(on_chord_error.s())).delay()
Chords may have callback and errback signatures linked to them, which addresses some of the issues with linking signatures to groups. Doing so will link the provided signature to the chord’s body which can be expected to gracefully invoke callbacks just once upon completion of the body, or errbacks just once if any task in the chord header or body fails.
chrod可能具有与之链接的 callback 和 errback 签名,这解决了将签名链接到group的一些问题。 这样做会将提供的签名链接到chrod的主体,可以预期在主体完成时优雅地调用回调一次,或者如果chrod标头或主体中的任何任务失败,则仅返回一次。
Important Notes:重要提示
使用chord的任务必须不能忽略results。在实践中这意味着你必须开启result_backend 才能使用chrods。此外,如果设置了task_ignore_result 为True,请务必保证chrod中的任务定义了ignore_result=False 。适用于Task子类和装饰器任务。This applies to both Task subclasses and decorated tasks.
Task子类示例:
class MyTask(Task):
ignore_result = False
装饰器任务示例:
@app.task(ignore_result=False)
def another_task(project):
do_something()
默认情况下,同步步骤是通过让一个周期性任务每秒轮询一次组的完成情况,并在准备就绪时调用签名来实现的。
示例:
from celery import maybe_signature
@app.task(bind=True)
def unlock_chord(self, group, callback, interval=1, max_retries=None):
if group.ready():
return maybe_signature(callback).delay(group.join())
raise self.retry(countdown=interval, max_retries=max_retries)
这被用于除了Redis和Memcached之外的所有结果后端:header中的每个任务之后计数器都会递增,然后在计数器超过集合中的任务数时应用回调。
Redis和Memcached方法是一个更好的解决方案,但在其他后端中不容易实现(欢迎提出建议!)。
Note:
Redis2.2之前Chrods不可用。
Note:
如果你在 Redis 结果后端使用 chords 并且还覆盖了
Task.after_return()方法,你需要确保调用super方法,否则chord回调将不会被应用。def after_return(self, *args, **kwargs): do_something() super().after_return(*args, **kwargs)
Map & Starmap
mapand starmap are built-in tasks that call the provided calling task for every element in a sequence.
他们与group的区别在于:
- 仅发送一个任务消息。
- 操作是顺序的。
比如使用map:
>>> from proj.tasks import add
>>> ~xsum.map([range(10), range(100)])
[45, 4950]
等同于:
@app.task
def temp():
return [xsum(range(10)), xsum(range(100))]
使用starmap:
>>> ~add.starmap(zip(range(10), range(10)))
[0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
等同于:
@app.task
def temp():
return [add(i, i) for i in range(10)]
这两个也是签名对象,所以也可以和其他签名或groups组合,比如:
>>> add.starmap(zip(range(10), range(10))).apply_async(countdown=10)
Chunks
Chunking让你把一个可迭代的工作分成几部分,比如有一个百万级别的对象,你可以创建10个任务,那每个任务就只有10W个对象。
有些人可能担心分块你的任务会导致并行度下降,但这对于繁忙的集群来说很少是真的,在实践中,因为你避免了消息传递的开销,它可能会大大提高性能。
使用app.Task.chunks()创建chunks 签名。
>>> add.chunks(zip(range(100), range(100)), 10)
As with https://docs.celeryq.dev/en/stable/reference/celery.html#celery.groupgroup`` the act of sending the messages for the chunks will happen in the current process when called:
>>> from proj.tasks import add
>>> res = add.chunks(zip(range(100), range(100)), 10)()
>>> res.get()
[[0, 2, 4, 6, 8, 10, 12, 14, 16, 18],
[20, 22, 24, 26, 28, 30, 32, 34, 36, 38],
[40, 42, 44, 46, 48, 50, 52, 54, 56, 58],
[60, 62, 64, 66, 68, 70, 72, 74, 76, 78],
[80, 82, 84, 86, 88, 90, 92, 94, 96, 98],
[100, 102, 104, 106, 108, 110, 112, 114, 116, 118],
[120, 122, 124, 126, 128, 130, 132, 134, 136, 138],
[140, 142, 144, 146, 148, 150, 152, 154, 156, 158],
[160, 162, 164, 166, 168, 170, 172, 174, 176, 178],
[180, 182, 184, 186, 188, 190, 192, 194, 196, 198]]
while calling .apply_async will create a dedicated task so that the individual tasks are applied in a worker instead:
调用 .apply_async时将创建一个专用任务,以便将各个任务应用于worker:
>>> add.chunks(zip(range(100), range(100)), 10).apply_async()
可以将chunks转换为group:
>>> group = add.chunks(zip(range(100), range(100)), 10).group()
and with the group skew the countdown of each task by increments of one:
>>> group.skew(start=1, stop=10)()
这意味着第一个任务将有一秒的倒计时,第二个任务将有两秒的倒计时,依此类推。